ネットワーク障害試験時のトラブル事例~HSRP~
ネットワークエンジニアの現場を担当しているK.Kです。
今回は障害試験時に経験した技術的なトラブル事例と対処内容を紹介します。
※ネットワーク構成は紹介用に簡易的な情報へ置き換えています。
前提
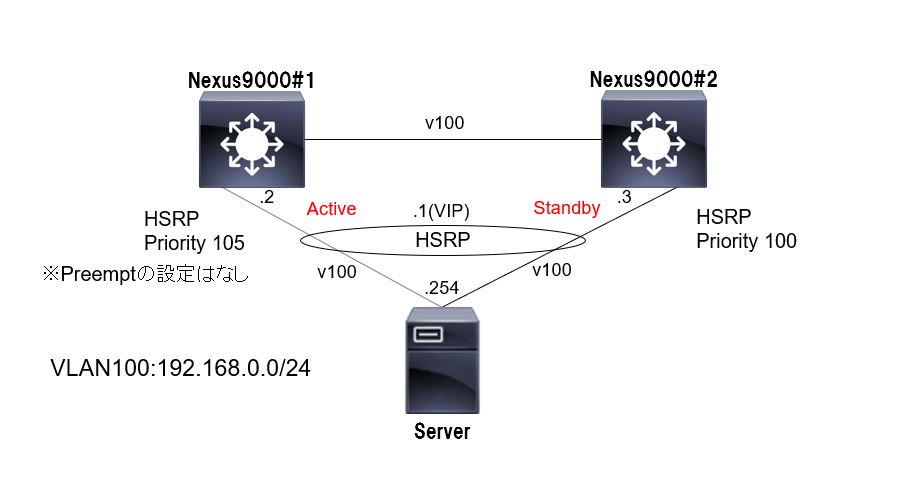
構築したネットワーク機器はL3用途でのNexus9000シリーズです。96ポートとかなり多くのポートを搭載しています。
サーバはVLAN100のIPが割り振られており、サーバのGWとなるIPとしてNexusにてHSRPのVIPを組んでいます。
HSRP_Helloパケットのやりとりは系間にて実装されています。
HSRP_Priorityは1号機が105、2号機が100としており、1号機の方が大きい値としています。
Preemptの設定は無しとしています。
想定外事象
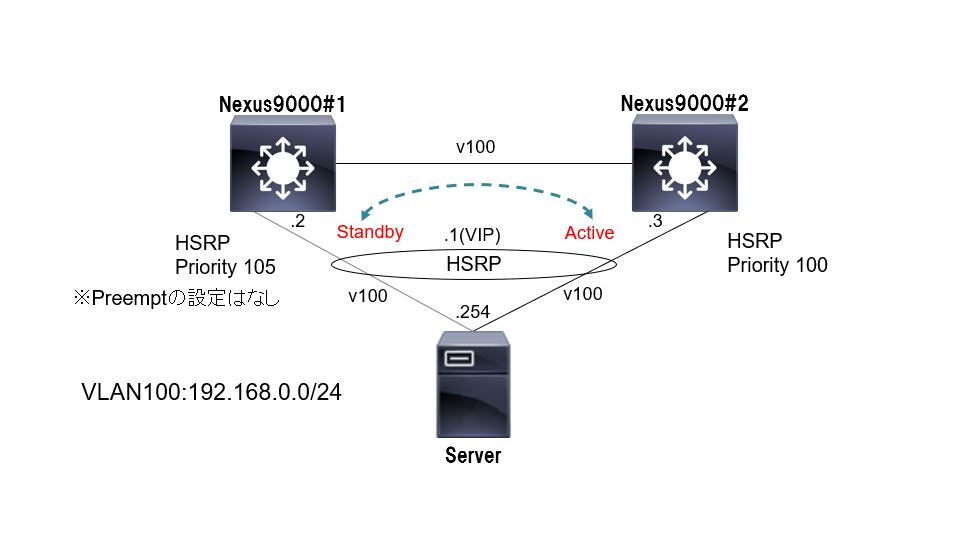
1号機の筐体障害→復旧をした際にPreemptの設定が無いにも関わらず、HSRPのActiveが1号機へ切り戻ってしまいました。
本来であれば、1号機の筐体障害時にActiveが2号機へ遷移し、1号機復旧時はActiveがそのまま2号機となる想定でした。
(↓想定の状態。2号機がActiveのまま。)
原因
原因は1号機の復旧時において各物理ポートがLinkUPするまでにかかる時間に差があるため、大谷翔平選手のように二刀流(両機Active)となってしまったことでした。
細かく解説します。
HSRP_Helloのやりとりしている物理ポートは遅番のEth1/95、Eth1/96(Port-channel)です。
そして、サーバとの接続ポートは若番のEth1/1となります。
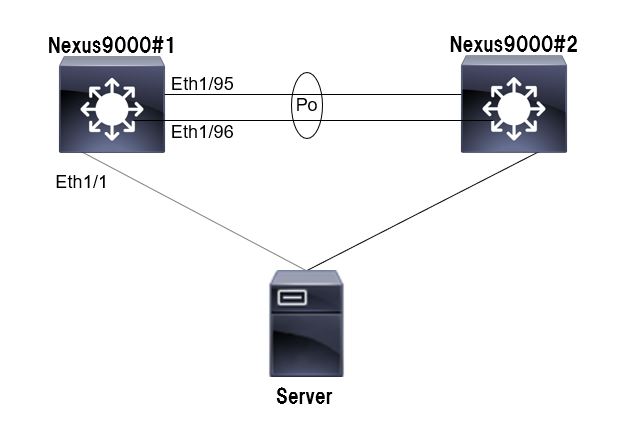
1号機の復旧からHSRPの組み込み完了までの挙動を確認すると次の通りでした。
①1号機のEth1/1がLinkUPします。同時にEth1/1にアサインされているVLAN100がLinkUPし、VLAN100のHSRPが起動します。
②24秒ほど経過すると1号機のVLAN100のHSRPの状態がActiveへ遷移します。
③35秒ほど経過すると1号機のEth1/95-96がLinkUPします。
④Eth1/95-96を通してHSRP_Helloパケットのやり取りが開始されると
1,2号機の両機がActiveの状態で衝突してしまい、Priorityが高い1号機がActiveを奪ってしまったことがわかりました。
今回構築したNexusは復旧時にEth1/1から順番にLinkUPし、最後のポートがLinkUPするまでに数十秒かかる仕様でした。
(機種は違いますが②で24秒とした根拠として適当な環境下でのHSRPの状態遷移時間例をdebugログで示します)
*Oct 16 23:45:51.352: HSRP: Gi0/2 Grp 10 Disabled -> Init
*Oct 16 23:45:52.376: HSRP: Gi0/2 Grp 10 Init -> Listen
*Oct 16 23:46:02.536: HSRP: Gi0/2 Grp 10 Listen -> Speak
*Oct 16 23:46:13.439: HSRP: Gi0/2 Grp 10 Speak -> Standby
*Oct 16 23:46:14.831: HSRP: Gi0/2 Grp 10 Standby -> Active
対策
以下、HSRPの起動を遅らせるオプション設定を追加することで、Eth1/1がLinkUP(=V100がUp)時点から120秒経過後、HSRPのやりとりを開始するように設定できました。
(config)# interface vlan 100
(config-if)# hsrp delay reload 120 ★再起動コマンドreloadを実施した場合
(config-if)# hsrp delay minimum 120 ★電源復旧した場合
※120という値でなくても、Helloパケットをやりとりする系間ポートがLinkUPする時間以上を設定してあげれば良いです。
これで、1号機復旧時はHSRP_Helloパケットのやりとり開始の際に2号機Activeのまま状態遷移せずにNexus#1がStandbyとして組み込まれることが確認できました。
最後に
今回はCatalyst3000シリーズからのリプレースでした。
機種が変わることで同じ設定内容でも挙動が変わることを再認識できました。
今後はこのような特殊な事例に限らずグループメンバーの底上げができるような内容を発信していきます。
最後までお読みいただき、ありがとうございました。